diff-sim benchmark
A unified benchmark of eight differentiable rigid-body simulators (May 2026).
Eight differentiable rigid-body simulators wired into a single
SimulatorAdapter contract, exercised by five experiments and a
shared methodology gate. Targeted venue: ICRA 2027.
TL;DR — gradient correctness on the Franka Panda
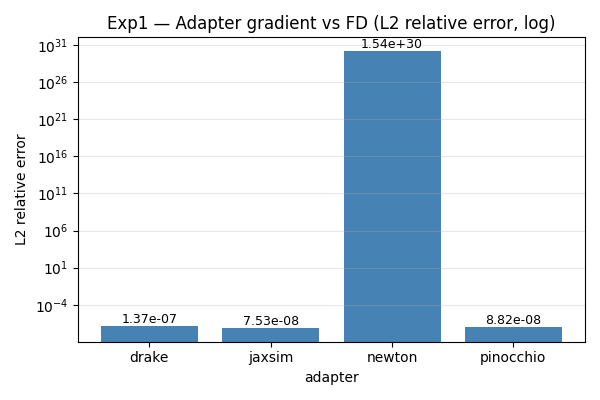
The headline result. Each adapter’s gradient_rollout_cost is
compared against a central finite-difference reference at $h = \sqrt{\epsilon}$
on a 5-step rollout of the Franka Panda from $q = 0$, $v = 0$ with
random torques.
| Adapter | rel. $L^2$ | rel. $L^\infty$ | cosine sim. | status |
|---|---|---|---|---|
| pinocchio | 8.82 × 10⁻⁸ | 1.88 × 10⁻⁷ | 1.0000 | ok |
| drake | 1.37 × 10⁻⁷ | 2.42 × 10⁻⁷ | 1.0000 | ok |
| jaxsim | 7.53 × 10⁻⁸ | 9.72 × 10⁻⁸ | 1.0000 | ok |
| brax | — | — | — | failed (Panda MJCF upstream bug) |
| mjx | 1.00 | 1.00 | −0.13 | failed (sm_120 XLA compile pathology) |
| newton | 1.5 × 10³⁰ | 7.2 × 10²⁹ | 0.00 | failed (tape contamination on Panda; ok on chain) |
| genesis | — | — | — | gradient not exposed in Python |
| tds | — | — | — | gradient bindings absent from the wheel |
Three of eight adapters (Pinocchio analytical RBD, Drake AutoDiffXd,
JaxSim jax.grad) agree with FD to one part in $10^7$. The remaining
five fail in different and informative ways, summarised in the
findings section below.
Robots in the benchmark
Four robots are loadable through the adapter contract. Panda and the parametric chain are exercised by every experiment; Go2, G1, and Allegro landed in Phase 3 and are wired through forward dynamics + floating-base SE(3) integration, but the locomotion / manipulation task suite (Phase 4+) is still ahead.

7-DoF arm, fixed base. Used by Exp1/2/5.

12-DoF quadruped + 6-DoF floating base. Phase 3.

29-DoF humanoid + 6-DoF floating base. Phase 3.

16-DoF dexterous hand, fixed base. Phase 3.
A parametric chain robot (planar N-link revolute, $N \in {3, 6, 12, 24, 48}$) is also used for the scaling sweep (Exp3) and the learning experiment (Exp4 on chain_3).
Other experiments
Exp2 — wall-clock timing on the Panda
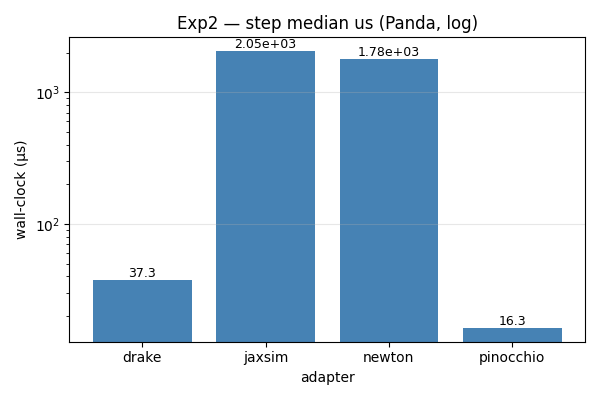
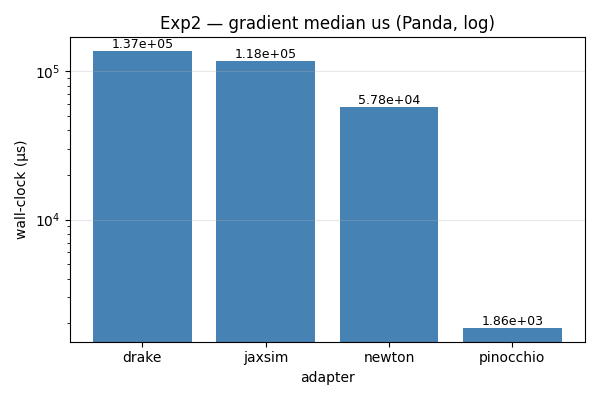
Pinocchio analytical ABA: 16 µs/step, 1.9 ms/gradient — the obvious
floor. Drake’s AutoDiffXd is 2× slower per step but still 50× faster
than the JAX-traced paths (JaxSim, Newton) at this size.
Exp3 — scaling with chain DoF count
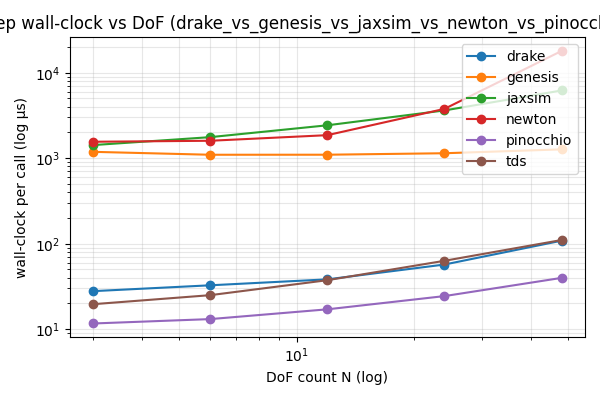
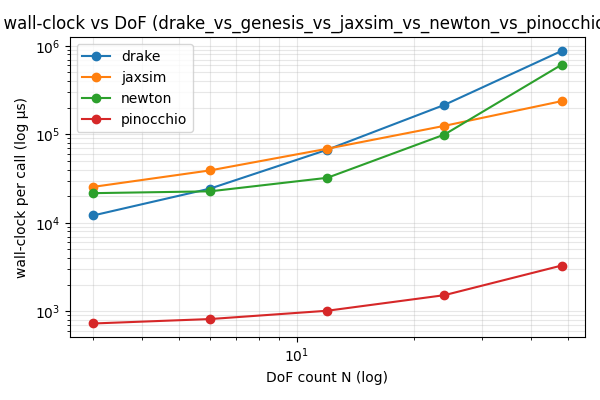
Pinocchio’s step exponent $b \approx 0.46$ confirms ABA’s empirical near-linear cost. Genesis is flat: Taichi kernel-launch overhead dominates the actual integration at these sizes.
Exp4 — gradient-based (SHAC) vs gradient-free (CEM)
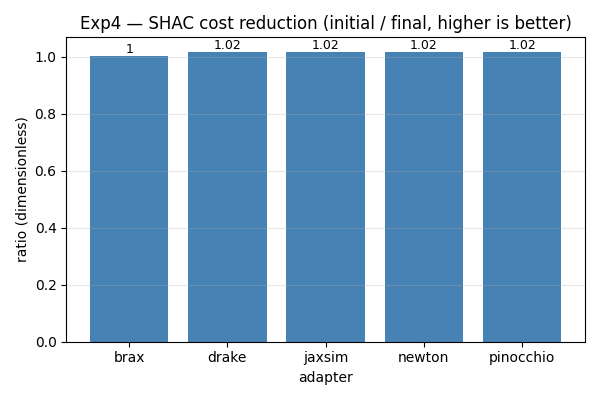
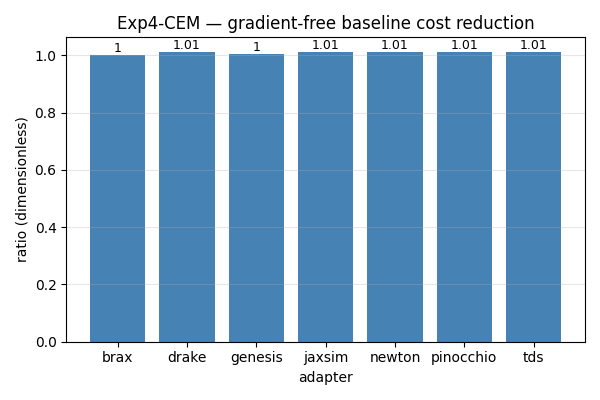
Methodology gate: the four gradient-capable adapters that work on chain_3 (Drake, JaxSim, Newton, Pinocchio) reduce cost by 1.02× — identical to four digits. That confirms the gradient signal is being delivered and used the same way across implementations.
Exp5 — import/load/first-step time + LOC
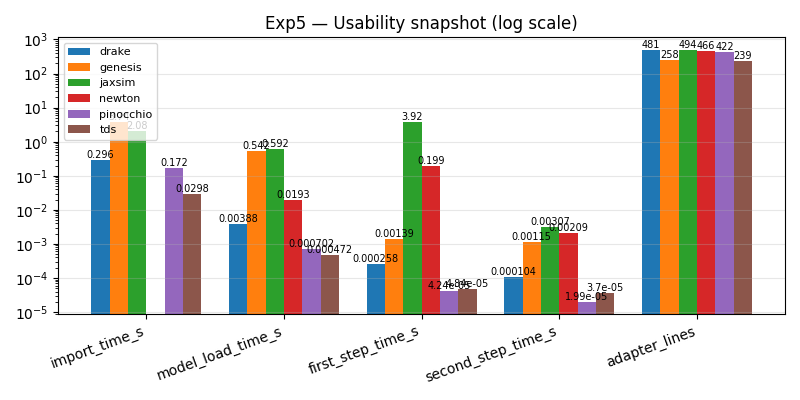
JAX initialization eats ~3.9 s of JaxSim’s first step; Newton’s 200 ms first step is Warp’s JIT kernel compile. Adapter LOC sits in a narrow 239–494 range across all eight — the contract is at the right level of abstraction.
Findings
-
MJX on sm_120 (RTX 5060).
jit_rollout_costtakes ~60 min of XLA compilation and produces a gradient with cosine similarity $-0.13$ vs FD. Reproducible; isolated to the newest Blackwell SASS. -
Brax pipeline vs menagerie Panda.
generalized.pipeline.initraises avmapshape mismatch on the Panda MJCF. Chain models compile fine — upstream Brax (deprecated) is unlikely to be fixed. -
Differentiable but not in Python. Genesis exposes gradients
only via a checkpoint-style
sim.sub_step_grad()API that doesn’t compose with a pure-functiongradient_rollout_costcontract. TDS’s pip wheel ships the plain-doubleinstantiation only; CppAD bindings exist in-tree but aren’t wired into Python. -
Newton gravity sign. Newton stores gravity as a signed scalar
along
up_vector; passing the positive vector norm (the obvious thing) flipped gravity skyward. Caught by the cross-adapter pendulum-agreement test. -
Newton gradient correct on chain, broken on Panda. Same
warp.Tapecode path reproduces FD to 0.5% rel. error on the 3-DoF chain ($\epsilon = 10^{-2}$) but produces cosine = 0 on Panda Exp1. Looks like tape-state contamination across the FD reference’s ~45 perturbations; per-perturbation fresh tape is the obvious next thing to try.
Reproducibility
git clone https://github.com/shubhamsingh91/sim_diff
cd sim_diff
DOCKER_BUILDKIT=0 docker build -t simdiff-bench:dev -f docker/Dockerfile .
./scripts/reproduce.sh
First run is ~30 min (clones robot_descriptions repos, builds JIT
caches). Subsequent runs hit warm caches → ~5 min for the non-MJX
adapters; MJX on sm_120 stays at ~60 min because of the documented
XLA-compile pathology. All numbers above are single-seed; multi-seed
CI bars + a contact-rich locomotion task suite are the next
milestone.
To run a single adapter:
docker run --rm --gpus all -v "$PWD:/workspace" -w /workspace \
simdiff-bench:dev \
python scripts/run_phase1.py --output-dir results/phase1 --adapter pinocchio